
GstInference/Example pipelines/NANO: Difference between revisions
No edit summary |
m (→InceptionV1) |
||
| (4 intermediate revisions by the same user not shown) | |||
| Line 2: | Line 2: | ||
{{GstInference/Head|previous=Example pipelines/PC|next=Example pipelines/TX2|title=GstInference GStreamer pipelines for Jetson NANO}} | {{GstInference/Head|previous=Example pipelines/PC|next=Example pipelines/TX2|title=GstInference GStreamer pipelines for Jetson NANO}} | ||
</noinclude> | </noinclude> | ||
<!-- If you want a custom title for the page, un-comment and edit this line: | <!-- If you want a custom title for the page, un-comment and edit this line: | ||
{{DISPLAYTITLE:GstInference - <descriptive page name>|noerror}} | {{DISPLAYTITLE:GstInference - <descriptive page name>|noerror}} | ||
| Line 10: | Line 11: | ||
}} | }} | ||
<br> | <br> | ||
<table> | |||
<tr> | |||
<td><div class="clear; float:right">__TOC__</div></td> | |||
<td valign=top> | |||
{{GStreamer debug}} | {{GStreamer debug}} | ||
</td> | |||
</table> | |||
== Tensorflow == | == Tensorflow == | ||
| Line 26: | Line 34: | ||
INPUT_LAYER='input' | INPUT_LAYER='input' | ||
OUTPUT_LAYER='InceptionV4/Logits/Predictions' | OUTPUT_LAYER='InceptionV4/Logits/Predictions' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | ||
multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ | multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ | ||
| Line 48: | Line 58: | ||
INPUT_LAYER='input' | INPUT_LAYER='input' | ||
OUTPUT_LAYER='InceptionV4/Logits/Predictions' | OUTPUT_LAYER='InceptionV4/Logits/Predictions' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | ||
filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ | filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ | ||
| Line 68: | Line 80: | ||
INPUT_LAYER='input' | INPUT_LAYER='input' | ||
OUTPUT_LAYER='InceptionV4/Logits/Predictions' | OUTPUT_LAYER='InceptionV4/Logits/Predictions' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | ||
v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ | v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ | ||
| Line 89: | Line 103: | ||
OUTPUT_LAYER='InceptionV4/Logits/Predictions' | OUTPUT_LAYER='InceptionV4/Logits/Predictions' | ||
LABELS='imagenet_labels.txt' | LABELS='imagenet_labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
gst-launch-1.0 \ | gst-launch-1.0 \ | ||
v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | ||
| Line 98: | Line 114: | ||
*Output | *Output | ||
[[File:Inceptionv2 barber.png|center|thumb|inceptionv2_barberchair]] | [[File:Inceptionv2 barber.png|center|thumb|inceptionv2_barberchair|link=]] | ||
=== InceptionV1 === | === InceptionV1 === | ||
| Line 108: | Line 124: | ||
<br> | <br> | ||
'''Server Pipeline''' which runs on the host PC | '''Server Pipeline''' which runs on the host PC | ||
* You will need to install a RidgeRun proprietary [ | * You will need to install a RidgeRun proprietary [[GstRtspSink | gst-rtsp-sink]] plugin on the PC. Please [[GstInference/Contact_us | contact Ridegrun]] | ||
<syntaxhighlight lang=bash> | <syntaxhighlight lang=bash> | ||
| Line 124: | Line 140: | ||
'''Install dependencies on the NANO board''' | '''Install dependencies on the NANO board''' | ||
<syntaxhighlight lang="bash" line='line' style="background-color: | <!---- | ||
<syntaxhighlight lang="bash" line='line' style="background-color:FFFF66"> | |||
---> | |||
<syntaxhighlight lang="bash" line="line" style="background-color:#FFFF66; color:blue;"> | |||
sudo apt install \ | sudo apt install \ | ||
libgstrtspserver-1.0-dev \ | libgstrtspserver-1.0-dev \ | ||
| Line 140: | Line 159: | ||
OUTPUT_LAYER='InceptionV1/Logits/Predictions/Reshape_1' | OUTPUT_LAYER='InceptionV1/Logits/Predictions/Reshape_1' | ||
export CUDA_VISIBLE_DEVICES=-1 | export CUDA_VISIBLE_DEVICES=-1 | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=inceptionv1:6 gst-launch-1.0 -e rtspsrc location="rtsp://<server_ip_address>:5000/stream1" ! queue ! rtph265depay ! queue ! h265parse ! queue ! omxh265dec ! queue ! nvvidconv ! queue ! net.sink_model inceptionv1 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER | GST_DEBUG=inceptionv1:6 gst-launch-1.0 -e rtspsrc location="rtsp://<server_ip_address>:5000/stream1" ! queue ! rtph265depay ! queue ! h265parse ! queue ! omxh265dec ! queue ! nvvidconv ! queue ! net.sink_model inceptionv1 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER | ||
</syntaxhighlight> | </syntaxhighlight> | ||
| Line 163: | Line 184: | ||
INPUT_LAYER='input/Placeholder' | INPUT_LAYER='input/Placeholder' | ||
OUTPUT_LAYER='add_8' | OUTPUT_LAYER='add_8' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | ||
multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ | multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ | ||
| Line 180: | Line 203: | ||
INPUT_LAYER='input/Placeholder' | INPUT_LAYER='input/Placeholder' | ||
OUTPUT_LAYER='add_8' | OUTPUT_LAYER='add_8' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | ||
filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ | filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ | ||
| Line 202: | Line 227: | ||
INPUT_LAYER='input/Placeholder' | INPUT_LAYER='input/Placeholder' | ||
OUTPUT_LAYER='add_8' | OUTPUT_LAYER='add_8' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | ||
v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ | v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ | ||
| Line 221: | Line 248: | ||
OUTPUT_LAYER='add_8' | OUTPUT_LAYER='add_8' | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
gst-launch-1.0 \ | gst-launch-1.0 \ | ||
v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | ||
| Line 230: | Line 259: | ||
*Output | *Output | ||
[[File:TinyYolo barber chair label.png|center|thumb|tinyYolo barber chair by tinyYolo]] | [[File:TinyYolo barber chair label.png|center|thumb|tinyYolo barber chair by tinyYolo|link=]] | ||
===FaceNet=== | ===FaceNet=== | ||
| Line 245: | Line 274: | ||
LABELS='$PATH_TO_GST_INFERENCE_ROOT_DIR/tests/examples/embedding/embeddings/labels.txt' | LABELS='$PATH_TO_GST_INFERENCE_ROOT_DIR/tests/examples/embedding/embeddings/labels.txt' | ||
EMBEDDINGS='$PATH_TO_GST_INFERENCE_ROOT_DIR/tests/examples/embedding/embeddings/embeddings.txt' | EMBEDDINGS='$PATH_TO_GST_INFERENCE_ROOT_DIR/tests/examples/embedding/embeddings/embeddings.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
gst-launch-1.0 \ | gst-launch-1.0 \ | ||
v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | ||
| Line 266: | Line 297: | ||
MODEL_LOCATION='graph_inceptionv4.tflite' | MODEL_LOCATION='graph_inceptionv4.tflite' | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | ||
multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ | multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ | ||
| Line 287: | Line 320: | ||
MODEL_LOCATION='graph_inceptionv4.tflite' | MODEL_LOCATION='graph_inceptionv4.tflite' | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | ||
filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ | filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ | ||
| Line 306: | Line 341: | ||
MODEL_LOCATION='graph_inceptionv4.tflite' | MODEL_LOCATION='graph_inceptionv4.tflite' | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ | ||
v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ | v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ | ||
| Line 325: | Line 362: | ||
MODEL_LOCATION='graph_inceptionv4.tflite' | MODEL_LOCATION='graph_inceptionv4.tflite' | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
gst-launch-1.0 \ | gst-launch-1.0 \ | ||
v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | ||
| Line 334: | Line 373: | ||
*Output | *Output | ||
[[File:Inceptionv2 barber.png|center|thumb|inceptionv2_barberchair]] | [[File:Inceptionv2 barber.png|center|thumb|inceptionv2_barberchair|link=]] | ||
=== InceptionV1 === | === InceptionV1 === | ||
| Line 344: | Line 383: | ||
<br> | <br> | ||
'''Server Pipeline''' which runs on the host PC | '''Server Pipeline''' which runs on the host PC | ||
* You will need to install a RidgeRun proprietary [ | * You will need to install a RidgeRun proprietary [[GstRtspSink | gst-rtsp-sink]] plugin on the PC. Please [[GstInference/Contact_us | contact Ridegrun]] | ||
<syntaxhighlight lang=bash> | <syntaxhighlight lang=bash> | ||
| Line 360: | Line 399: | ||
'''Install dependencies on the NANO board''' | '''Install dependencies on the NANO board''' | ||
<!----- | |||
<syntaxhighlight lang="bash" line='line' style="background-color:cornsilk"> | <syntaxhighlight lang="bash" line='line' style="background-color:cornsilk"> | ||
----> | |||
<syntaxhighlight lang="bash" line="line" style="background-color:#FFFF66; color:blue;"> | |||
sudo apt install \ | sudo apt install \ | ||
libgstrtspserver-1.0-dev \ | libgstrtspserver-1.0-dev \ | ||
| Line 375: | Line 417: | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
export CUDA_VISIBLE_DEVICES=-1 | export CUDA_VISIBLE_DEVICES=-1 | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=inceptionv1:6 gst-launch-1.0 -e rtspsrc location="rtsp://<server_ip_address>:5000/stream1" ! queue ! rtph265depay ! queue ! h265parse ! queue ! omxh265dec ! queue ! nvvidconv ! queue ! net.sink_model inceptionv1 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)" | GST_DEBUG=inceptionv1:6 gst-launch-1.0 -e rtspsrc location="rtsp://<server_ip_address>:5000/stream1" ! queue ! rtph265depay ! queue ! h265parse ! queue ! omxh265dec ! queue ! nvvidconv ! queue ! net.sink_model inceptionv1 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)" | ||
</syntaxhighlight> | </syntaxhighlight> | ||
| Line 397: | Line 441: | ||
MODEL_LOCATION='graph_tinyyolov2.tflite' | MODEL_LOCATION='graph_tinyyolov2.tflite' | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | ||
multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ | multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ | ||
| Line 413: | Line 459: | ||
MODEL_LOCATION='graph_tinyyolov2.tflite' | MODEL_LOCATION='graph_tinyyolov2.tflite' | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ | ||
filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ | filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ | ||
| Line 430: | Line 478: | ||
MODEL_LOCATION='graph_tinyyolov2_tensorflow.pb' | MODEL_LOCATION='graph_tinyyolov2_tensorflow.pb' | ||
LABELS='labels.txt' | LABELS='labels.txt' | ||
</syntaxhighlight> | |||
<syntaxhighlight lang=bash> | |||
gst-launch-1.0 \ | gst-launch-1.0 \ | ||
v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ | ||
| Line 439: | Line 489: | ||
*Output | *Output | ||
[[File:TinyYolo barber chair label.png|center|thumb|tinyYolo barber chair by tinyYolo]] | [[File:TinyYolo barber chair label.png|center|thumb|tinyYolo barber chair by tinyYolo|link=]] | ||
Latest revision as of 12:02, 21 May 2024
Make sure you also check GstInference's companion project: R2Inference |
| GstInference |
|---|
| Introduction |
| Getting started |
| Supported architectures |
|
InceptionV1 InceptionV3 YoloV2 AlexNet |
| Supported backends |
|
Caffe |
| Metadata and Signals |
| Overlay Elements |
| Utils Elements |
| Legacy pipelines |
| Example pipelines |
| Example applications |
| Benchmarks |
| Model Zoo |
| Project Status |
| Contact Us |
 |
The following pipelines are deprecated and kept only as reference. If you are using v0.7 and above, please check our sample pipelines on the Example Pipelines section. |
|
Tensorflow
InceptionV4
- Get the graph used on this example from this link.
- You will need an image file from one of ImageNet classes.
- Use the following pipelines as examples for different scenarios.
Image file
IMAGE_FILE='cat.jpg' MODEL_LOCATION='graphs/InceptionV4_TensorFlow/graph_inceptionv4_tensorflow.pb' INPUT_LAYER='input' OUTPUT_LAYER='InceptionV4/Logits/Predictions'
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ inceptionv4 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER
- Output
0:00:41.102961125 9500 0x55cd3e54a0 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 282 : (0,651213) 0:00:41.103261600 9500 0x55cd3e54a0 LOG inceptionv4 gstinceptionv4.c:208:gst_inceptionv4_preprocess:<net> Preprocess 0:00:41.414504525 9500 0x55cd3e54a0 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:41.415032923 9500 0x55cd3e54a0 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 282 : (0,651213) 0:00:41.415468297 9500 0x55cd3e54a0 LOG inceptionv4 gstinceptionv4.c:208:gst_inceptionv4_preprocess:<net> Preprocess 0:00:41.726504445 9500 0x55cd3e54a0 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess
Video file
VIDEO_FILE='cat.mp4' MODEL_LOCATION='graphs/InceptionV4_TensorFlow/graph_inceptionv4_tensorflow.pb' INPUT_LAYER='input' OUTPUT_LAYER='InceptionV4/Logits/Predictions'
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ inceptionv4 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER
- Output
0:00:43.428868204 9619 0x55b19b6b70 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:43.436573728 9619 0x55b19b6b70 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 282 : (0,875079) 0:00:43.473135944 9619 0x55b19b6b70 LOG inceptionv4 gstinceptionv4.c:208:gst_inceptionv4_preprocess:<net> Preprocess 0:00:43.861247785 9619 0x55b19b6b70 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:43.861550447 9619 0x55b19b6b70 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 282 : (0,872448)
Camera stream
CAMERA='/dev/video0' MODEL_LOCATION='graphs/InceptionV4_TensorFlow/graph_inceptionv4_tensorflow.pb' INPUT_LAYER='input' OUTPUT_LAYER='InceptionV4/Logits/Predictions'
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ inceptionv4 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER
- Output
0:00:47.149540519 9748 0x5592110b20 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:47.149877140 9748 0x5592110b20 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 283 : (0,702133) 0:00:47.150562517 9748 0x5592110b20 LOG inceptionv4 gstinceptionv4.c:208:gst_inceptionv4_preprocess:<net> Preprocess 0:00:47.460348086 9748 0x5592110b20 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:47.460709916 9748 0x5592110b20 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 283 : (0,705862)
Visualization with classification overlay
CAMERA='/dev/video0' MODEL_LOCATION='graphs/InceptionV4_TensorFlow/graph_inceptionv4_tensorflow.pb' INPUT_LAYER='input' OUTPUT_LAYER='InceptionV4/Logits/Predictions' LABELS='imagenet_labels.txt'
gst-launch-1.0 \ v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ t. ! videoconvert ! videoscale ! queue ! net.sink_model \ t. ! queue ! net.sink_bypass \ inceptionv4 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER \ net.src_bypass ! videoconvert ! classificationoverlay labels="$(cat $LABELS)" font-scale=4 thickness=4 ! videoconvert ! xvimagesink sync=false
- Output
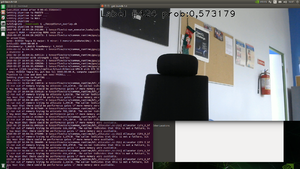
InceptionV1
RTSP Camera stream
- Get the graph used on this example from this link
- You will need a v4l2 compatible camera
Server Pipeline which runs on the host PC
- You will need to install a RidgeRun proprietary gst-rtsp-sink plugin on the PC. Please contact Ridegrun
gst-launch-1.0 -e v4l2src device=/dev/video0 ! video/x-raw, format=YUY2, width=640, height=480, framerate=30/1 ! videoconvert ! video/x-raw, format=I420, width=640, height=480, framerate=30/1 ! queue ! x265enc option-string="keyint=30:min-keyint=30:repeat-headers=1" ! video/x-h265, width=640, height=480, mapping=/stream1 ! queue ! rtspsink service=5000
- Output
Setting pipeline to PAUSED ... Pipeline is live and does not need PREROLL ... Setting pipeline to PLAYING ... New clock: GstSystemClock Redistribute latency...
Install dependencies on the NANO board
sudo apt install \ libgstrtspserver-1.0-dev \ libgstreamer1.0-dev \ libgstreamer-plugins-base1.0-dev \ libgstreamer-plugins-good1.0-dev \ libgstreamer-plugins-bad1.0-dev
Client Pipeline which runs on the NANO board
CAMERA='/dev/video0' MODEL_LOCATION='graph_inceptionv1_tensorflow.pb' INPUT_LAYER='input' OUTPUT_LAYER='InceptionV1/Logits/Predictions/Reshape_1' export CUDA_VISIBLE_DEVICES=-1
GST_DEBUG=inceptionv1:6 gst-launch-1.0 -e rtspsrc location="rtsp://<server_ip_address>:5000/stream1" ! queue ! rtph265depay ! queue ! h265parse ! queue ! omxh265dec ! queue ! nvvidconv ! queue ! net.sink_model inceptionv1 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER
- Output
0:00:08.679606626 10086 0x5599c01cf0 LOG inceptionv1 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 665 : (0.295041) 0:00:08.679695321 10086 0x5599c01cf0 LOG inceptionv1 gstinceptionv1.c:142:gst_inceptionv1_preprocess:<net> Preprocess 0:00:08.892169471 10086 0x5599c01cf0 LOG inceptionv1 gstinceptionv1.c:153:gst_inceptionv1_postprocess:<net> Postprocess 0:00:08.892256499 10086 0x5599c01cf0 LOG inceptionv1 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 665 : (0.256458) 0:00:08.892378058 10086 0x5599c01cf0 LOG inceptionv1 gstinceptionv1.c:142:gst_inceptionv1_preprocess:<net> Preprocess 0:00:09.101159620 10086 0x5599c01cf0 LOG inceptionv1 gstinceptionv1.c:153:gst_inceptionv1_postprocess:<net> Postprocess 0:00:09.101244877 10086 0x5599c01cf0 LOG inceptionv1 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 665 : (0.243692)
TinyYoloV2
- Get the graph used on this example from this link
- You will need an image file from one of TinyYOLO classes
Image file
IMAGE_FILE='cat.jpg' MODEL_LOCATION='graphs/TinyYoloV2_TensorFlow/graph_tinyyolov2_tensorflow.pb' INPUT_LAYER='input/Placeholder' OUTPUT_LAYER='add_8'
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ tinyyolov2 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER
- Output
0:00:24.558985002 9909 0x557d3278a0 LOG tinyyolov2 gsttinyyolov2.c:288:gst_tinyyolov2_postprocess:<net> Postprocess 0:00:24.576012429 9909 0x557d3278a0 LOG tinyyolov2 gstinferencedebug.c:92:gst_inference_print_boxes:<net> Box: [class:7, x:5,710080, y:115,575158, width:345,341579, height:304,490976, prob:14,346013]
Video file
VIDEO_FILE='cat.mp4' MODEL_LOCATION='graphs/TinyYoloV2_TensorFlow/graph_tinyyolov2_tensorflow.pb' INPUT_LAYER='input/Placeholder' OUTPUT_LAYER='add_8'
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ tinyyolov2 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER
- Output
0:00:07.245722660 30545 0x5ad000 LOG tinyyolov2 gsttinyyolov2.c:479:gst_tinyyolov2_preprocess:<net> Preprocess 0:00:07.360377432 30545 0x5ad000 LOG tinyyolov2 gsttinyyolov2.c:501:gst_tinyyolov2_postprocess:<net> Postprocess 0:00:07.360586455 30545 0x5ad000 LOG tinyyolov2 gsttinyyolov2.c:384:print_top_predictions:<net> Box: [class:7, x:-46.105452, y:-9.139365, width:445.139551, height:487.967720, prob:14.592537]
Camera stream
- Get the graph used on this example from this link
- You will need a camera compatible with Nvidia Libargus API or V4l2.
- LABELS and EMBEDDINGS files are in $PATH_TO_GST_INFERENCE_ROOT_DIR/tests/examples/embedding/embeddings.
CAMERA='/dev/video0' MODEL_LOCATION='graphs/TinyYoloV2_TensorFlow/graph_tinyyolov2_tensorflow.pb' INPUT_LAYER='input/Placeholder' OUTPUT_LAYER='add_8'
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ tinyyolov2 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER
- Output
0:00:39.754924355 5030 0x10ee590 LOG tinyyolov2 gsttinyyolov2.c:479:gst_tinyyolov2_preprocess:<net> Preprocess 0:00:39.876816786 5030 0x10ee590 LOG tinyyolov2 gsttinyyolov2.c:501:gst_tinyyolov2_postprocess:<net> Postprocess 0:00:39.876914225 5030 0x10ee590 LOG tinyyolov2 gsttinyyolov2.c:384:print_top_predictions:<net> Box: [class:4, x:147.260736, y:116.184709, width:134.389472, height:245.113627, prob:8.375733]
Visualization with detection overlay
CAMERA='/dev/video1' MODEL_LOCATION='graph_tinyyolov2_tensorflow.pb' INPUT_LAYER='input/Placeholder' OUTPUT_LAYER='add_8' LABELS='labels.txt'
gst-launch-1.0 \ v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ t. ! videoconvert ! videoscale ! queue ! net.sink_model \ t. ! queue ! net.sink_bypass \ tinyyolov2 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER \ net.src_bypass ! videoconvert ! detectionoverlay labels="$(cat $LABELS)" font-scale=1 thickness=2 ! videoconvert ! xvimagesink sync=false
- Output

FaceNet
Visualization with detection overlay
- Get the graph used on this example from this link
- You will need a camera compatible with Nvidia Libargus API or V4l2.
- LABELS and EMBEDDINGS files are in $PATH_TO_GST_INFERENCE_ROOT_DIR/tests/examples/embedding/embeddings.
CAMERA='/dev/video1' MODEL_LOCATION='graph_facenetv1_tensorflow.pb' INPUT_LAYER='input' OUTPUT_LAYER='output' LABELS='$PATH_TO_GST_INFERENCE_ROOT_DIR/tests/examples/embedding/embeddings/labels.txt' EMBEDDINGS='$PATH_TO_GST_INFERENCE_ROOT_DIR/tests/examples/embedding/embeddings/embeddings.txt'
gst-launch-1.0 \ v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ t. ! videoconvert ! videoscale ! queue ! net.sink_model \ t. ! queue ! net.sink_bypass \ facenetv1 name=net model-location=$MODEL_LOCATION backend=tensorflow backend::input-layer=$INPUT_LAYER backend::output-layer=$OUTPUT_LAYER \ net.src_bypass ! videoconvert ! embeddingoverlay labels="$(cat $LABELS)" embeddings="$(cat $EMBEDDINGS)" font-scale=4 thickness=4 ! videoconvert ! xvimagesink sync=false
Tensorflow Lite
InceptionV4
- Get the graph used on this example from this link.
- You will need an image file from one of ImageNet classes.
- Use the following pipelines as examples for different scenarios.
Image file
IMAGE_FILE='cat.jpg' MODEL_LOCATION='graph_inceptionv4.tflite' LABELS='labels.txt'
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ inceptionv4 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)"
- Output
0:00:41.102961125 9500 0x55cd3e54a0 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 282 : (0,651213) 0:00:41.103261600 9500 0x55cd3e54a0 LOG inceptionv4 gstinceptionv4.c:208:gst_inceptionv4_preprocess:<net> Preprocess 0:00:41.414504525 9500 0x55cd3e54a0 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:41.415032923 9500 0x55cd3e54a0 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 282 : (0,651213) 0:00:41.415468297 9500 0x55cd3e54a0 LOG inceptionv4 gstinceptionv4.c:208:gst_inceptionv4_preprocess:<net> Preprocess 0:00:41.726504445 9500 0x55cd3e54a0 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess
Video file
VIDEO_FILE='cat.mp4' MODEL_LOCATION='graph_inceptionv4.tflite' LABELS='labels.txt'
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ inceptionv4 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)"
- Output
0:00:43.428868204 9619 0x55b19b6b70 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:43.436573728 9619 0x55b19b6b70 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 282 : (0,875079) 0:00:43.473135944 9619 0x55b19b6b70 LOG inceptionv4 gstinceptionv4.c:208:gst_inceptionv4_preprocess:<net> Preprocess 0:00:43.861247785 9619 0x55b19b6b70 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:43.861550447 9619 0x55b19b6b70 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 282 : (0,872448)
Camera stream
CAMERA='/dev/video0' MODEL_LOCATION='graph_inceptionv4.tflite' LABELS='labels.txt'
GST_DEBUG=inceptionv4:6 gst-launch-1.0 \ v4l2src device=$CAMERA ! videoconvert ! videoscale ! queue ! net.sink_model \ inceptionv4 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)"
- Output
0:00:47.149540519 9748 0x5592110b20 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:47.149877140 9748 0x5592110b20 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 283 : (0,702133) 0:00:47.150562517 9748 0x5592110b20 LOG inceptionv4 gstinceptionv4.c:208:gst_inceptionv4_preprocess:<net> Preprocess 0:00:47.460348086 9748 0x5592110b20 LOG inceptionv4 gstinceptionv4.c:219:gst_inceptionv4_postprocess:<net> Postprocess 0:00:47.460709916 9748 0x5592110b20 LOG inceptionv4 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 283 : (0,705862)
Visualization with classification overlay
CAMERA='/dev/video0' MODEL_LOCATION='graph_inceptionv4.tflite' LABELS='labels.txt'
gst-launch-1.0 \ v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ t. ! videoconvert ! videoscale ! queue ! net.sink_model \ t. ! queue ! net.sink_bypass \ inceptionv4 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)" \ net.src_bypass ! videoconvert ! inferenceoverlay font-scale=4 thickness=4 ! videoconvert ! xvimagesink sync=false
- Output
InceptionV1
RTSP Camera stream
- Get the graph used on this example from this link
- You will need a v4l2 compatible camera
Server Pipeline which runs on the host PC
- You will need to install a RidgeRun proprietary gst-rtsp-sink plugin on the PC. Please contact Ridegrun
gst-launch-1.0 -e v4l2src device=/dev/video0 ! video/x-raw, format=YUY2, width=640, height=480, framerate=30/1 ! videoconvert ! video/x-raw, format=I420, width=640, height=480, framerate=30/1 ! queue ! x265enc option-string="keyint=30:min-keyint=30:repeat-headers=1" ! video/x-h265, width=640, height=480, mapping=/stream1 ! queue ! rtspsink service=5000
- Output
Setting pipeline to PAUSED ... Pipeline is live and does not need PREROLL ... Setting pipeline to PLAYING ... New clock: GstSystemClock Redistribute latency...
Install dependencies on the NANO board
sudo apt install \ libgstrtspserver-1.0-dev \ libgstreamer1.0-dev \ libgstreamer-plugins-base1.0-dev \ libgstreamer-plugins-good1.0-dev \ libgstreamer-plugins-bad1.0-dev
Client Pipeline which runs on the NANO board
CAMERA='/dev/video0' MODEL_LOCATION='graph_inceptionv1.tflite' LABELS='labels.txt' export CUDA_VISIBLE_DEVICES=-1
GST_DEBUG=inceptionv1:6 gst-launch-1.0 -e rtspsrc location="rtsp://<server_ip_address>:5000/stream1" ! queue ! rtph265depay ! queue ! h265parse ! queue ! omxh265dec ! queue ! nvvidconv ! queue ! net.sink_model inceptionv1 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)"
- Output
0:00:08.679606626 10086 0x5599c01cf0 LOG inceptionv1 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 665 : (0.295041) 0:00:08.679695321 10086 0x5599c01cf0 LOG inceptionv1 gstinceptionv1.c:142:gst_inceptionv1_preprocess:<net> Preprocess 0:00:08.892169471 10086 0x5599c01cf0 LOG inceptionv1 gstinceptionv1.c:153:gst_inceptionv1_postprocess:<net> Postprocess 0:00:08.892256499 10086 0x5599c01cf0 LOG inceptionv1 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 665 : (0.256458) 0:00:08.892378058 10086 0x5599c01cf0 LOG inceptionv1 gstinceptionv1.c:142:gst_inceptionv1_preprocess:<net> Preprocess 0:00:09.101159620 10086 0x5599c01cf0 LOG inceptionv1 gstinceptionv1.c:153:gst_inceptionv1_postprocess:<net> Postprocess 0:00:09.101244877 10086 0x5599c01cf0 LOG inceptionv1 gstinferencedebug.c:73:gst_inference_print_highest_probability:<net> Highest probability is label 665 : (0.243692)
TinyYoloV2
- Get the graph used on this example from this link
- You will need an image file from one of TinyYOLO classes
Image file
IMAGE_FILE='cat.jpg' MODEL_LOCATION='graph_tinyyolov2.tflite' LABELS='labels.txt'
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ multifilesrc location=$IMAGE_FILE ! jpegparse ! nvjpegdec ! 'video/x-raw' ! nvvidconv ! 'video/x-raw(memory:NVMM),format=NV12' ! nvvidconv ! queue ! net.sink_model \ tinyyolov2 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)"
- Output
0:00:24.558985002 9909 0x557d3278a0 LOG tinyyolov2 gsttinyyolov2.c:288:gst_tinyyolov2_postprocess:<net> Postprocess 0:00:24.576012429 9909 0x557d3278a0 LOG tinyyolov2 gstinferencedebug.c:92:gst_inference_print_boxes:<net> Box: [class:7, x:5,710080, y:115,575158, width:345,341579, height:304,490976, prob:14,346013]
Video file
VIDEO_FILE='cat.mp4' MODEL_LOCATION='graph_tinyyolov2.tflite' LABELS='labels.txt'
GST_DEBUG=tinyyolov2:6 gst-launch-1.0 \ filesrc location=$VIDEO_FILE ! qtdemux name=demux ! h264parse ! omxh264dec ! nvvidconv ! queue ! net.sink_model \ tinyyolov2 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)"
- Output
0:00:07.245722660 30545 0x5ad000 LOG tinyyolov2 gsttinyyolov2.c:479:gst_tinyyolov2_preprocess:<net> Preprocess 0:00:07.360377432 30545 0x5ad000 LOG tinyyolov2 gsttinyyolov2.c:501:gst_tinyyolov2_postprocess:<net> Postprocess 0:00:07.360586455 30545 0x5ad000 LOG tinyyolov2 gsttinyyolov2.c:384:print_top_predictions:<net> Box: [class:7, x:-46.105452, y:-9.139365, width:445.139551, height:487.967720, prob:14.592537]
Visualization with detection overlay
CAMERA='/dev/video1' MODEL_LOCATION='graph_tinyyolov2_tensorflow.pb' LABELS='labels.txt'
gst-launch-1.0 \ v4l2src device=$CAMERA ! "video/x-raw, width=1280, height=720" ! tee name=t \ t. ! videoconvert ! videoscale ! queue ! net.sink_model \ t. ! queue ! net.sink_bypass \ tinyyolov2 name=net model-location=$MODEL_LOCATION backend=tflite labels="$(cat $LABELS)" \ net.src_bypass ! videoconvert ! inferenceoverlay font-scale=1 thickness=2 ! videoconvert ! xvimagesink sync=false
- Output